はてなダイアリーからOctopressへの移行
I had another blog, hatena diary
技術系のエントリーに関しては、はてなダイアリーの方にブログを書いていたが、Octopressへの移行に際して、全部こっちに移動することにした。その時の手順を書いておく。
Firstly, you can export all entries from hatena diary
はてなダイアリーのデータは管理画面>データ管理>インポート/エクスポートからエクスポート出来る。
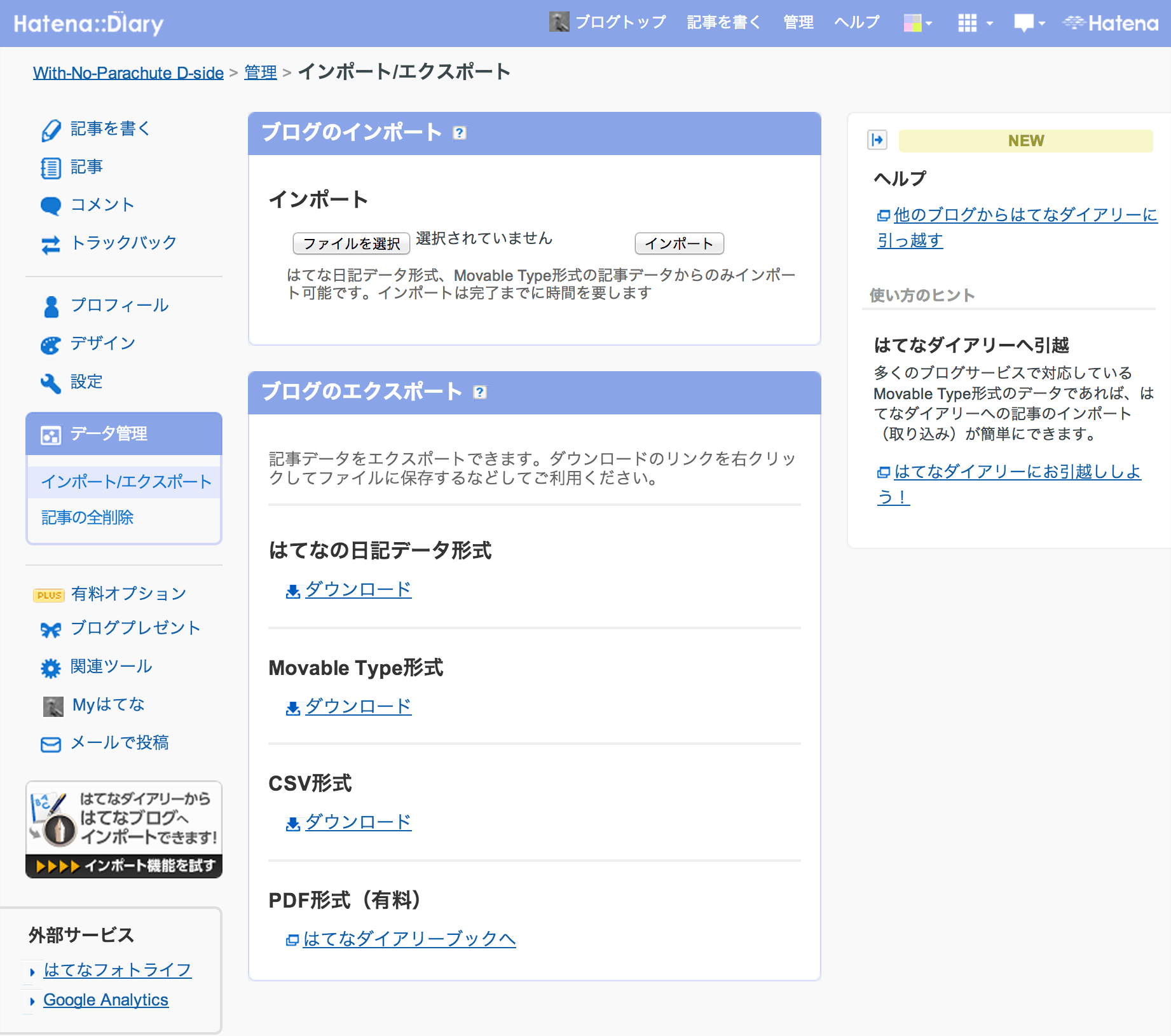
ここでは、Movable Type形式をダウンロードする。はてなの日記データ形式は、xml形式にも関わらず、同一日付で複数エントリーある場合でも、<day>タグのなかに複数のエントリーが入っていたため、パースするのがめんどくさかった。Movable Type形式でエクスポートしておくと、これらは別エントリーとして扱われるため、単純になる。
Movable Type decoder
Symfony Serializer componentの考え方からすると、ファイルフォーマットから配列への変換なので、ここの処理はdecodeというのが正しいはず。

中身は単純で、--------がエントリーの区切り、-----がデータの区切りとなっているようだ。詳細はThe Movable Type Import / Export Formatに書いてあるが、各エントリーの先頭にSingle-line Dataが置かれ、それに続くMulti-line Dataが-----で区切られる、というフォーマットらしい。
decodeの内容はこんなコードを書いた。手抜きなので、ただのfunctionだ。
Symfony\Component\Serializer\Encoder\DecoderInterfaceを実装して、なんてことはやってないし、Multi-line Dataはbodyしか読み取ってない。
<?php
function decodePost($data)
{
$lines = explode("\n", $data);
$readMeta = true;
$post = array();
$body = array();
$meta = null;
foreach ($lines as $line) {
if (preg_match('/^-----$/', $line, $matches)) {
$readMeta = true;
} elseif ($readMeta && preg_match('/^(?P<meta>[\w\s]+?)\:$/', $line, $matches)) {
$readMeta = false;
$meta = strtolower($matches['meta']);
} elseif ($readMeta && preg_match('/^(?P<meta>[\w\s]+?)\: (?P<value>.*)$/', $line, $matches)) {
$key = strtolower($matches['meta']);
$value = $matches['value'];
if (array_key_exists($key, $post)) {
if (is_array($post[$key])) {
$post[$key][] = $value;
} else {
$old = $post[$key];
$post[$key] = array($old, $value);
}
} else {
$post[$key] = $value;
}
} elseif ($meta === 'body') {
$body[] = $line;
}
}
$post['body'] = implode("\n", $body);
return $post;
}エントリーの区切りでファイルを分割してから、この関数を使ってそれぞれのエントリーをdecodeしていく。
hatena_diary2markdown.php
最終的には、こんなスクリプトを書いてOctopress用のmarkdownを生成した。なおhtmlからmarkdownへの変換はpandocを使用しているので、このスクリプトを実行する前にインストールしておく必要がある。
<?php
// decoder
function decodePost($data)
{
$lines = explode("\n", $data);
$readMeta = true;
$post = array();
$body = array();
$meta = null;
foreach ($lines as $line) {
if (preg_match('/^-----$/', $line, $matches)) {
$readMeta = true;
} elseif ($readMeta && preg_match('/^(?P<meta>[\w\s]+?)\:$/', $line, $matches)) {
$readMeta = false;
$meta = strtolower($matches['meta']);
} elseif ($readMeta && preg_match('/^(?P<meta>[\w\s]+?)\: (?P<value>.*)$/', $line, $matches)) {
$key = strtolower($matches['meta']);
$value = $matches['value'];
if (array_key_exists($key, $post)) {
if (is_array($post[$key])) {
$post[$key][] = $value;
} else {
$old = $post[$key];
$post[$key] = array($old, $value);
}
} else {
$post[$key] = $value;
}
} elseif ($meta === 'body') {
$body[] = $line;
}
}
$post['body'] = implode("\n", $body);
return $post;
}
function getPosts($path)
{
$contents = file_get_contents($path);
$postContents = preg_split("/\n--------\n/", $contents);
$posts = array();
foreach ($postContents as $data) {
$post = getPost($data);
if ($post !== null) {
$posts[] = $post;
}
}
return $posts;
}
function getPost($data)
{
$data = trim($data);
if (empty($data)) {
return null;
}
$post = decodePost($data);
// post process
// category
if (array_key_exists('category', $post)) {
$post['category'] = (array)$post['category'];
} else {
$post['category'] = array();
}
// to lower case
$post['category'] = categoryToLower($post['category']);
// date time
// "11/23/2009 00:09:52 PM"
if (isset($post['date'])) {
$post['datetime'] = \DateTime::createFromFormat('m/d/Y h:i:s A', $post['date']);
}
return $post;
}
function categoryToLower(array $categories)
{
$lowers = array();
foreach ($categories as $category) {
$lowers[] = strtolower($category);
}
return $lowers;
}
// converter
function toMarkdown(array $post)
{
$meta = toMetaMarkdown($post);
$dir = '_tmp';
if (!is_dir($dir)) {
mkdir($dir);
}
$body = toMarkdownBody($dir, $post['body']);
return sprintf("%s\n%s", $meta, $body);
}
function toMetaMarkdown(array $post)
{
$template = "---
layout: post
title: %s
date: %s
comments: false
categories: %s
published: false
---
";
if (!empty($post['category'])) {
$categories = sprintf('[%s]', implode(', ', $post['category']));
} else {
$categories = '';
}
return sprintf($template, $post['title'], $post['datetime']->format('Y-m-d H:i'), $categories);
}
function toMarkdownBody($dir, $body)
{
$bodyHtml = 'body.html';
$bodyPath = $dir . "/" . $bodyHtml;
file_put_contents($bodyPath, $body);
$filename = 'body.markdown';
$bodyMarkdownPath = $dir . "/" . $filename;
$cmd = sprintf('cd %s; pandoc -f html -t markdown %s -o %s', $dir, $bodyHtml, $filename);
exec($cmd, $output, $returnCode);
unlink($bodyPath);
if ($returnCode !== 0 || !empty($output)) {
throw new \RuntimeException('pandoc failure.');
}
$body = file_get_contents($bodyMarkdownPath);
unlink($bodyMarkdownPath);
return $body;
}
// dumper
function dump($dir, array $post)
{
$markdown = toMarkdown($post);
$filename = sprintf('%s-%s.markdown', $post['datetime']->format('Y-m-d'), $post['datetime']->format('YmdHis'));
$path = $dir . '/' . $filename;
file_put_contents($path, $markdown);
}
function dumpAll($dir, array $posts)
{
foreach ($posts as $post) {
dump($dir, $post);
}
}
// run
$dir = '_posts';
if (!is_dir($dir)) {
mkdir($dir);
}
$file = 'movable_type.txt';
$posts = getPosts($file);
dumpAll($dir, $posts);Conclusion
_postsディレクトリにxxx.markdownが出来上がっているはずなので、後はこれらのファイルをsource/_postsに移動すれば完了だ。
pandocを使うと妙なところで改行が入ってしまうので、なんとかしたかったが、方法が分からなかった。おそらくword wrapしているのだと思うが、オプションでなんとかなるのだろうか。